Mathematik der Tennis-Aufstellung
Dieter Süß · Spieler bei den Pionieren im UTC Krems-Süd · und wenn der Platz mal zu nass ist (obwohl zu nass und zu langsam gibt es eh nicht) Univ.-Prof. an der Fakultät für Physik der Universität Wien
Wann gewinnt man wirklich? Modell-Kalibrierung auf 24227 Einzel- und 11171 Doppel-Matches aus 5 NÖTV-Saisons (2022–2026) — kuratierter Datensatz aus 17 niederösterreichischen Vereinen. Die Doppel-ITN-Berechnung läuft separat über die volle NÖTV+WTV-Datenbank.
1 · Das Modell
Die Mannschaft hat in der allgemeinen Klasse nach den Einzeln eine Aufstellungs-Entscheidung zu treffen: 3 Doppel werden aus 6 Spielern gebildet. Diese Seite versucht aus den Statistiken vergangener Begegnungen herauszulesen, welche Paarung sich im Schnitt am ehesten lohnt — und wie viel Unterschied die Aufstellung statistisch überhaupt macht. Vorweggenommen: in vielen Fällen liegt der Vorteil der besten gegenüber der schlechtesten zulässigen Aufstellung nur bei wenigen Prozentpunkten Team-Sieg-Wahrscheinlichkeit; in knappen Begegnungen kann das jedoch entscheidend sein.
Wichtig: Alle Analysen auf dieser Seite (Abschnitte 1–9) verwenden die Gesamt-ITN (= offizielle ITN, basierend auf Einzel- und Doppel-Ergebnissen) des ÖTV als Eingangsgröße — also den offiziellen fedRank jedes Spielers. Das ist der Wert, den der NÖTV im Mannschaftsmeisterschafts-Roster führt. Im Abschnitt 4.2 zeigen wir den Vergleich: was passiert, wenn man statt der Gesamt-ITN unsere eigene Doppel-ITN als Prädiktor einsetzt.
Was hier nicht berücksichtigt wird: das Zusammenspiel eines Paares (Harmonie, eingespielte Routinen), Stilkombinationen (z. B. Aufschlag-Volley vs. Grundlinie) und die Tagesform nach den Einzeln. Das Modell ist also ein ITN-getriebener Mittelwert über viele Begegnungen, kein Match-Orakel für den Einzelfall.
Das statistische Modell:
P(wir gewinnen ein Doppel) = ½ · tanh((ITNGegner − ITNmein) / β) + ½
wo ITNmein und ITNGegner die Mittelwerte beider Spieler im jeweiligen Paar sind. Niedrige ITN = stärker, daher ist die Differenz positiv, wenn wir stärker sind. β hat die Einheit ITN und ist genau diejenige ITN-Differenz, bei der das stärkere Paar mit ca. 88 % gewinnt (charakteristische Skala des tanh).
2 · Datengrundlage
Wir haben alle NÖTV-Begegnungen von UTC Krems-Süd + 16 niederösterreichischen Gegnervereinen aus den Saisons 2021-06-08 bis 2026-05-21 via offizieller NÖTV-API extrahiert. Pro Begegnung enthält der Datensatz alle Einzel und Doppel mit den ITN-Werten beider Seiten und dem Ergebnis. Insgesamt: 24227 Einzel und 11171 Doppel.
Welche Vereine sind in der Stichprobe?
- UTC Krems-Süd
- UTK Langenlois
- UTC Hadersdorf-Kammern
- UTC Rohrendorf
- Tennisclub Stratzing-Droß
- UTK Mautern
- TC Grafenwörth-Feuersbrunn
- UTC Emmersdorf
- USV Furth bei Göttweig
- UTC Gedersdorf
- WSV Voest-Alpine Krems
- Tennisclub Eggenburg
- UTC Groß Siegharts
- UTC Waidhofen/Thaya
- UTC Krems-Mitterau
- SG Die Wachauer
- KTK Krems
17 NÖTV-Vereine, schwerpunktmäßig aus der Wachau, dem Kremser Raum und Waldviertel. UTC Krems-Süd ist in allen Begegnungen entweder Heim oder Gast; die 16 anderen sind unsere historischen Mannschaftsmeisterschafts-Gegner.
Welche Spieler-Klassen sind enthalten?
| Klasse | Einzel | Doppel |
|---|---|---|
| Allgemeine Klasse (Herren/Damen) | 16935 | 7926 |
| Senioren (35+, 45+, 55+, …) | 4034 | 2013 |
| Jugend / Kids | 3258 | 1232 |
Die meisten Datenpunkte stammen aus der Allgemeinen Klasse — dort spielen am meisten Mannschaften und die ITN-Werte sind am dichtesten besetzt. Senioren- und Jugend-Matches sind ebenfalls enthalten, weil das tanh-Modell skaleninvariant ist (eine ITN-Differenz von +0.5 hat überall dieselbe Bedeutung).
Welche ITN-Werte sind in der Stichprobe?
| Min | Median | Max | |
|---|---|---|---|
| Einzel-Spieler-ITN | 1.30 | 7.60 | 10.30 |
| Doppel-Paar-Mittel-ITN | 1.30 | 7.60 | 10.30 |
ITN-Skala: 1.0 = Weltklasse, 3.0–4.0 = Landesliga-Niveau, 6.0–7.0 = Hobby, 10.0 = Anfänger. Niedrig = stärker. Unsere Stichprobe deckt das Spektrum von Top-Spielern bis Anfänger ab, mit Schwerpunkt im Landesliga-/Hobby-Bereich.
3 · Einzel: Wann gewinnt man?
Das Einzel-Modell ergibt per Maximum-Likelihood-Fit:
P(Einzel-Sieg) = ½ · tanh((ITNGegner − ITNmein) / 1.03) + ½ [βS = 1.03 ITN]
Konvention im Chart unten: die x-Achse zeigt ITNGast − ITNHeim. Aus Sicht des Heim-Spielers ist das identisch mit ITNGegner − ITNmein.
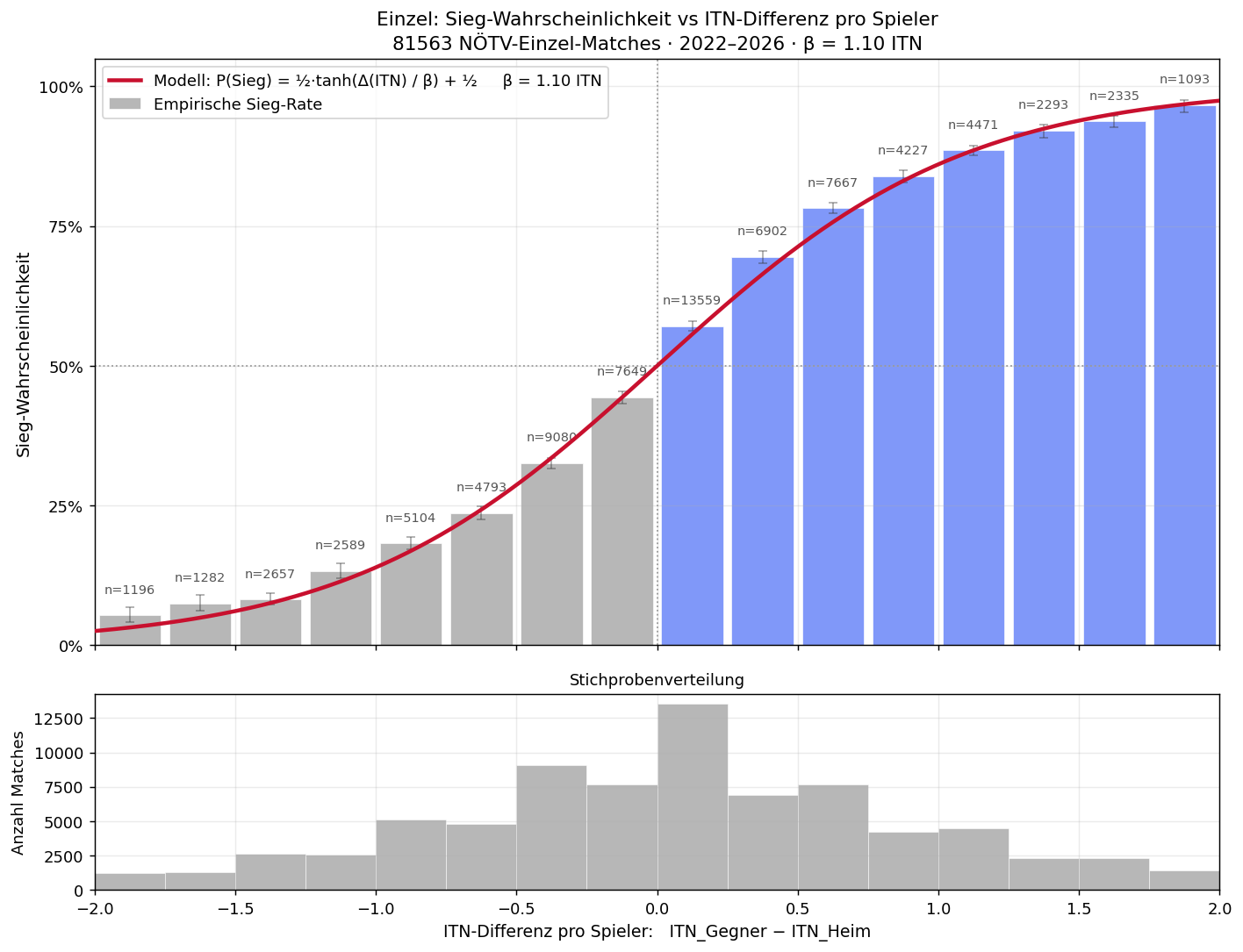
Was deutlich wird: bei ITN-Differenz +0.5 zwischen den beiden Einzel-Spielern (wir leicht stärker) gewinnt der Heim-Spieler ca. 70%. Bei +1.0 etwa 85%. Bei −0.5 (wir schwächer) sind's nur noch ~20–30%. Aber: bei knappen Differenzen (±0.2 ITN) ist's quasi 50:50 — pure Tagesform.
Konvention Einzel: ITN-Differenz = ITNGegner − ITNmein (jeweils das Per-Spieler-fedRank-Wert aus dem NÖTV-Roster).
4 · Doppel: Etwas berechenbarer
Konvention: was bedeutet „ITN" im Doppel?
Im Doppel hat jedes Paar zwei Spieler. Wir definieren konsistent durchgehend die Paar-ITN als arithmetisches Mittel der beiden Spieler:
ITNPaar = (ITNSpieler 1 + ITNSpieler 2) / 2
Beispiel: ein Paar mit Spielern ITN 3.0 und ITN 4.0 hat ITNPaar = 3.5. Die ITN-Differenz im Doppel ist demnach:
ITN-Differenz = ITNGegner-Paar − ITNunser-Paar
= (ITNG1 + ITNG2) / 2 − (ITNU1 + ITNU2) / 2
Damit haben Einzel und Doppel dieselbe Skala: „+0.5 ITN-Differenz" bedeutet bei beiden, dass die Gegen-Seite im Mittel 0.5 ITN schwächer ist. Bei Doppel-Summen-Sicht entspräche das einer Summen-Differenz von 1.0 ITN — aber wir bleiben durchgehend bei der Paar-Mittel-Konvention, weil:
- Skala-konsistent zwischen Einzel und Doppel
- Tagesform-Schwankungen werden im Mittel ausgeglichen → besserer Prädiktor
- Direkt vergleichbar mit Per-Spieler-ITN
Das Doppel-Modell mit dieser Konvention:
P(Doppel-Sieg) = ½ · tanh((ITNGegner-Paar − ITNunser-Paar) / βD) + ½ mit βD = 0.99 ITN (MLE-Fit auf 11171 Doppel-Matches)
β hat die Einheit ITN und ist die charakteristische ITN-Distanz: bei Δ(ITN) = β gewinnt das stärkere Paar mit ca. 88 % (= ½·tanh(1) + ½). Kleines β ⇒ kleine ITN-Unterschiede entscheiden schon klar; großes β ⇒ Modell ist „flacher", Tagesform spielt eine größere Rolle.
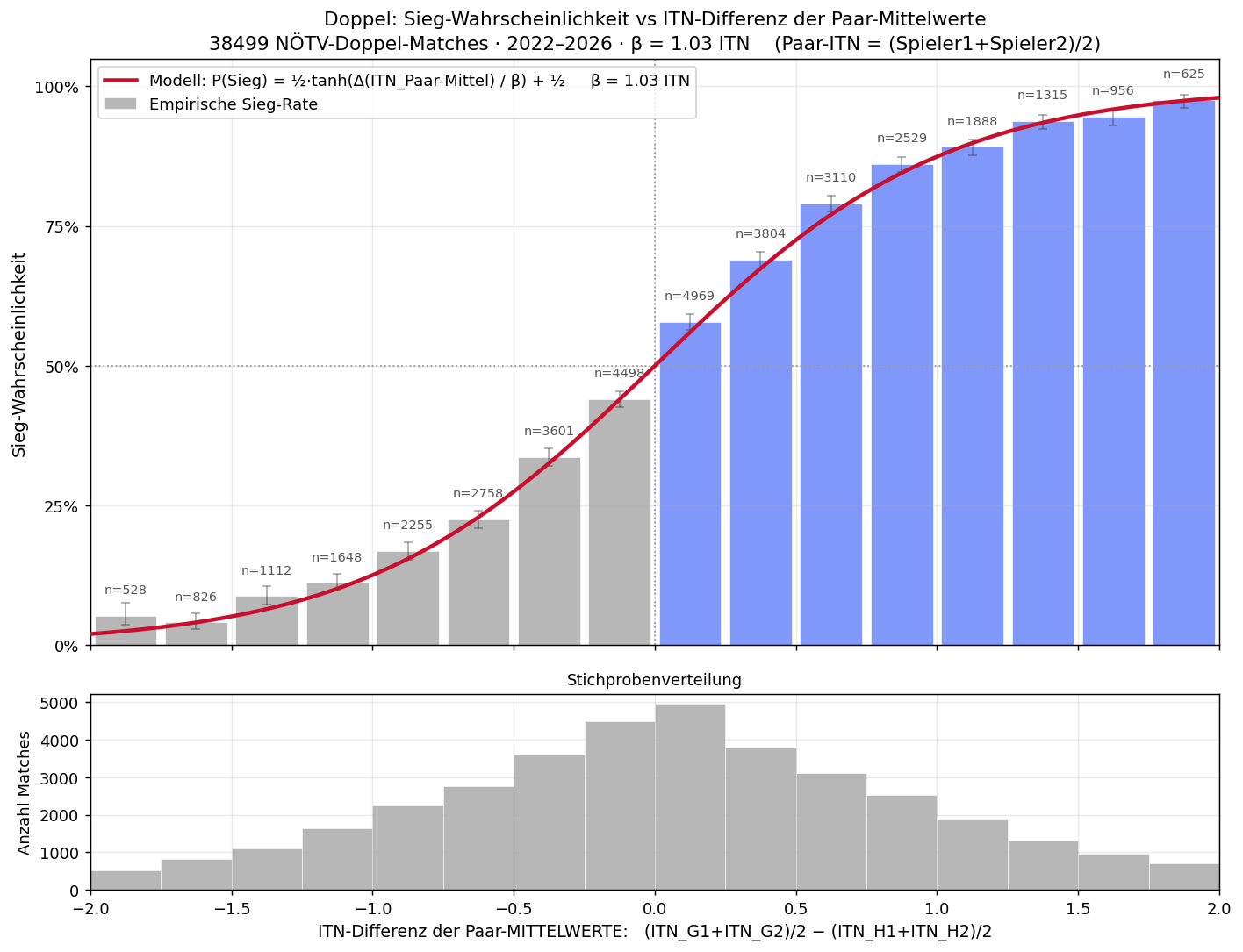
Doppel ist statistisch etwas berechenbarer als Einzel (βD = 0.99 ITN vs βS = 1.03 ITN — kleineres β heißt: schmälere ITN-Distanz reicht für die gleiche Sicherheit).
| ITN-Differenz | N | Siege | Empirisch | Modell |
|---|---|---|---|---|
| -3.0 – -0.5 | 2758 | 377 | 14% | 3% |
| -0.5 – -0.2 | 1416 | 494 | 35% | 33% |
| -0.2 – +0.2 | 2520 | 1285 | 51% | 50% |
| +0.2 – +0.5 | 1318 | 916 | 69% | 67% |
| +0.5 – +1.0 | 1609 | 1323 | 82% | 82% |
| +1.0 – +3.0 | 1474 | 1390 | 94% | 98% |
4.1 · Was β konkret bedeutet — Anschauliche Interpretation
Wir definieren β als die charakteristische ITN-Distanz (Einheit: ITN, im Nenner der Formel): bei Δ(ITN) = β gewinnt das stärkere Paar mit ca. 88 %. Das folgt aus tanh(1) ≈ 0.76 und damit P = ½ · 0.76 + ½ ≈ 88 %. β ist also die „natürliche Skala" des tanh-Modells: ein ITN-Unterschied in der Größenordnung von β entscheidet die Begegnung praktisch klar.
Für unser Doppel-β = 0.99 ITN: eine Paarung, die im Paar-Mittelwert etwa 1.03 ITN-Stufen stärker ist als die Gegner, gewinnt im Schnitt ~88 % aller Doppel.
| Δ(ITN) / β | Δ(ITN) bei β=0.99 | tanh-Wert | P(stärkeres Paar gewinnt) |
|---|---|---|---|
| 0.0 | 0.00 | 0.000 | 50 % (Gleichstand) |
| 0.25 | 0.25 | 0.245 | 62 % |
| 0.5 | 0.50 | 0.462 | 73 % |
| 0.75 | 0.74 | 0.635 | 82 % |
| 1.0 | 0.99 | 0.762 | 88 % (natürliche Skala — Δ(ITN) = β) |
| 1.5 | 1.49 | 0.905 | 95 % |
| 2.0 | 1.98 | 0.964 | 98 % |
| 3.0 | 2.97 | 0.995 | 99.7 % |
Eine alternative griffige Lesart: der erste β ≈ 0.99 ITN-Schritt lässt die Sieg-Wahrscheinlichkeit von 50 % auf 88 % springen (also +38 Prozentpunkte). Weitere β-Schritte bringen nur noch kleine Steigerungen — das tanh-Modell sättigt asymptotisch bei 100 %.
Für Einzel ist βS ≈ 1.03 ITN — sehr ähnlich wie Doppel. Kleines β = berechenbarer. Doppel ist tendenziell minimal berechenbarer als Einzel, weil bei Paaren die individuelle Tagesform statistisch ausgemittelt wird.
4.2 · Gesamt-ITN vs. Doppel-ITN als Prädiktor
Alle bisherigen Analysen verwenden die Gesamt-ITN (= offizielle ITN, basierend auf Einzel- und Doppel-Ergebnissen) des ÖTV. Macht unsere eigene Doppel-ITN die Vorhersage besser? Wir haben denselben MLE-Fit auf denselben 46.478 Matches mit beiden Prädiktoren durchgeführt:
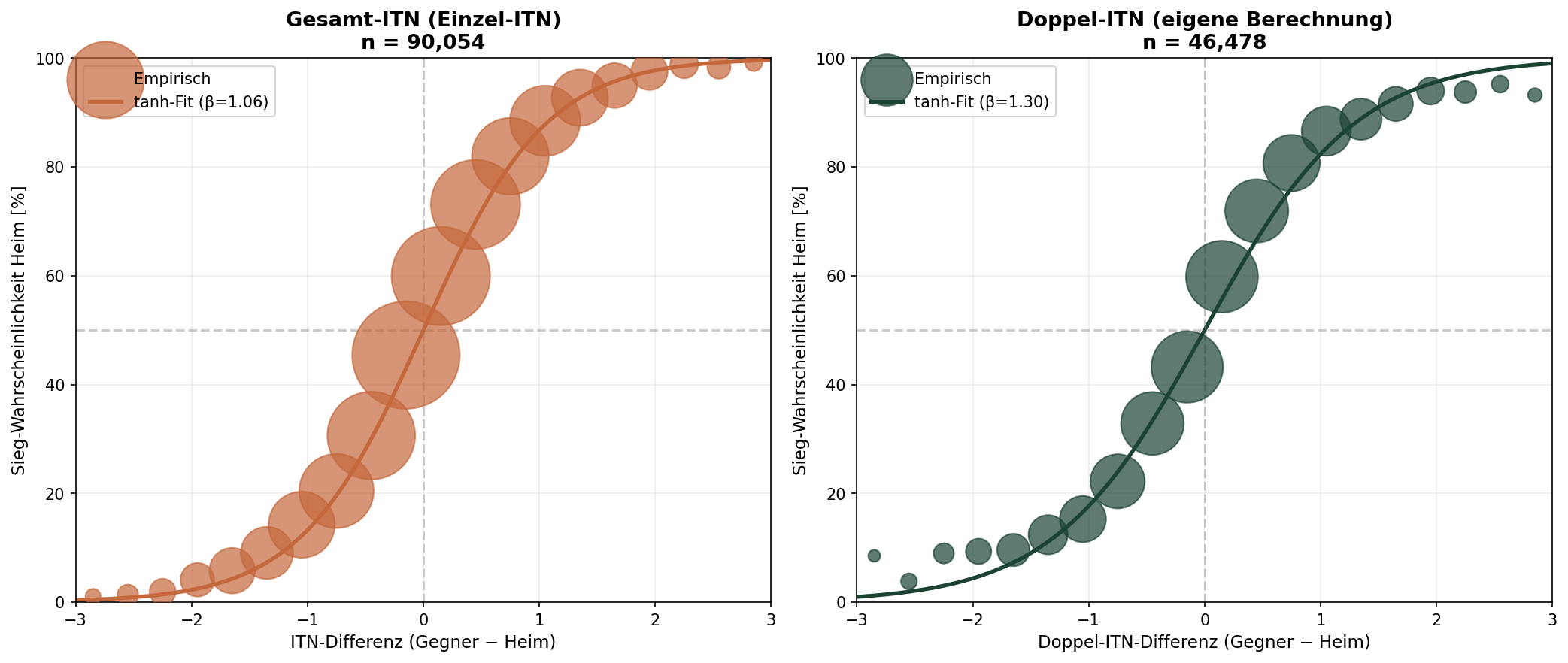
| Prädiktor | β [ITN] | Log-Likelihood | n (identisch) |
|---|---|---|---|
| Gesamt-ITN (Einzel-fedRank) | 1.06 | −22.699 | 46.478 |
| Doppel-ITN (eigene Berechnung) | 1.30 | −24.142 | 46.478 |
Die Gesamt-ITN liefert auf denselben Matches eine höhere Log-Likelihood (ΔLL = 1.443). Ein Vuong-Test (Modellvergleich für nicht-geschachtelte Modelle) ergibt eine Teststatistik von z = 18.2 (p < 10−70) — der Unterschied ist hoch signifikant.
Was heißt das konkret? Einfachster Test: wir fragen für jedes Match „wer ist Favorit?" (= bessere ITN) und prüfen, ob der Favorit tatsächlich gewinnt:
| Prädiktor | Richtig | von | Quote |
|---|---|---|---|
| Gesamt-ITN | 35.740 | 46.478 | 76,9 % |
| Doppel-ITN | 34.915 | 46.478 | 75,1 % |
In 86 % der Matches sind sich beide einig. Dort, wo sie sich widersprechen (6.371 Matches), hat die Gesamt-ITN in 53 % der Fälle recht, die Doppel-ITN in 47 % — ein Vorteil, aber kein dramatischer.
Aufschlüsselung nach ITN-Differenz — die Gesamtquote (76,9 % vs 75,1 %) mittelt über alle Matches, auch solche mit winziger ITN-Differenz, wo „Favorit" quasi Münzwurf ist. Pro Bucket:
| ITN-Differenz | n | Gesamt-ITN richtig | Doppel-ITN richtig | Diff |
|---|---|---|---|---|
| < 0,2 (knapp) | 8.304 | 53,6 % | 58,8 % | Doppel +5,2 pp |
| 0,2 – 0,5 | 10.445 | 66,3 % | 64,0 % | Gesamt +2,2 pp |
| 0,5 – 1,0 | 13.603 | 79,2 % | 76,5 % | Gesamt +2,7 pp |
| 1,0 – 1,5 | 7.777 | 89,9 % | 88,1 % | Gesamt +1,8 pp |
| 1,5 – 2,0 | 3.768 | 95,0 % | 94,2 % | Gesamt +0,8 pp |
| ≥ 2,0 | 2.581 | 98,7 % | 98,2 % | Gesamt +0,5 pp |
Bei knappen Matches (ITN-Differenz < 0,2 — das sind 18 % aller Matches) ist die Doppel-ITN tatsächlich der bessere Prädiktor (+5,2 Prozentpunkte). Sie unterscheidet dort besser, wer wirklich der Favorit ist — die Gesamt-ITN sieht bei diesen Spielern quasi keinen Unterschied, die Doppel-ITN schon. Bei größeren Differenzen (≥ 0,2) gewinnt die Gesamt-ITN durchgehend, weil sie von der ÖTV-Glättung profitiert und auf mehr Datenpunkten pro Spieler basiert (s. Abschnitt 9.4).
Die Doppel-ITN ist also nicht einfach „schlechter" — sie hat ihre Stärke bei knappen Begegnungen, wo die offizielle ITN zu wenig differenziert. Als eigenständige Kennzahl zeigt sie, wie gut jemand spezifisch im Doppel performt.
5 · Mathematik: P(mindestens k Doppel-Siege)
Für die Captain-Entscheidung interessiert nicht die Sieg-Wahrscheinlichkeit eines einzelnen Doppels, sondern die Wahrscheinlichkeit, mindestens 1, mindestens 2 oder alle 3 Doppel zu gewinnen. Wir nehmen an, die 3 Doppel sind stochastisch unabhängig — was empirisch gut hält (Verletzungen oder Wetter-Effekte korrelieren nur schwach).
Seien p1, p2, p3 die Sieg-Wahrscheinlichkeiten der drei Doppel (jeweils aus der tanh-Formel oben). Dann gilt für die exakte Anzahl gewonnener Doppel:
P(genau 0) = (1−p1)·(1−p2)·(1−p3) P(genau 1) = p1·(1−p2)·(1−p3) + (1−p1)·p2·(1−p3) + (1−p1)·(1−p2)·p3 P(genau 2) = p1·p2·(1−p3) + p1·(1−p2)·p3 + (1−p1)·p2·p3 P(genau 3) = p1·p2·p3
Daraus die kumulativen Wahrscheinlichkeiten (≥k Siege):
P(≥1 Sieg) = 1 − P(genau 0) = 1 − (1−p1)·(1−p2)·(1−p3) P(≥2 Siege) = P(genau 2) + P(genau 3) P(≥3 Siege) = P(genau 3) = p1·p2·p3
Beispiel: bei drei knappen Doppeln mit je p = 60% ergibt sich:
- P(≥1) = 1 − 0.4³ = 93.6% — fast sicher mindestens einer
- P(≥2) = 3·0.6²·0.4 + 0.6³ = 64.8% — Mehrheits-Sieg wahrscheinlich
- P(≥3) = 0.6³ = 21.6% — Vollsieg deutlich unwahrscheinlicher
Im Doppelrechner wird zusätzlich der Minimax-Filter angewandt: für jede unserer Aufstellungen wird die für uns ungünstigste Gegner-Aufstellung gewählt; angezeigt wird die schlechteste zu erwartende P(≥k). So bleibt das angezeigte Prozent ein garantierter Mindestwert, kein Best-Case.
6 · Wie wählt man die Aufstellung? (Minimax)
Der Captain weiß vor dem Doppel nicht, wie der Gegner-Captain seine 6 Spieler paart. Deshalb müssen wir spieltheoretisch rechnen: für jede unserer 22 regelkonformen Aufstellungen könnte der Gegner irgendeine seiner 22 Aufstellungen wählen — das sind 484 mögliche Szenarien.
Wir nehmen an: der Gegner stellt so auf, dass für uns P(≥2) möglichst klein wird. Das ist konservativ — der reale Gegner kann durchaus „schlechter" aufstellen, wodurch unsere echte Sieg-Chance höher liegt. Aber wir verschenken nie eine Garantie.
Konkret rechnet der Solver:
Für jede unserer 22 Aufstellungen u: p_garantiert(u) = min über alle 22 Gegner-Aufstellungen g von P(≥2 | u, g) Minimax-Aufstellung = argmax über u von p_garantiert(u)
Übersetzt: zuerst stellt sich für jede unserer Wahlen die für uns ungünstigste Gegner-Antwort ein (das innere Minimum). Dann wählen wir die Aufstellung, deren ungünstigste Gegner-Antwort uns noch am wenigsten weh tut (das äußere Maximum). Das Ergebnis ist ein garantierter Mindestwert, kein Best-Case.
7 · Konkretes Beispiel: Spielbericht 1. Mannschaft
UTC Krems-Süd 3 vs Tennisclub Eggenburg 3 · 2026-05-10 · Allgemeine Klasse
Stand nach den 6 Einzeln: 2:4 (zurück!). Es musste ein Doppel-Sieg her — der Captain hatte folgende 6 Spieler in der Aufstellung, beide Teams nach ITN aufsteigend sortiert (Platzziffer 1 = stärkster):
UTC Krems-Süd
- Gleiss M. (ITN 6.00)
- Haselmayer (ITN 6.30)
- Gleiss P. (ITN 6.50)
- Koll (ITN 7.00)
- Lintner (ITN 7.50)
- Hessel (ITN 8.10)
Tennisclub Eggenburg 3
- Grill (ITN 6.20)
- Rohm (ITN 6.60)
- Veit-Egerer (ITN 6.60)
- Soukup (ITN 6.80)
- Bauer (ITN 7.30)
- Heimberger (ITN 7.30)
7.1 · Tatsächlich gespielte Aufstellung — Modell-Prognose vs Realität
Beide Seiten haben (sortiert nach ITN) so paariert:
| D | Heim-Paar | ITN-Mittel | Gast-Paar | ITN-Mittel | Diff | pi (Modell) | tatsächlich |
|---|---|---|---|---|---|---|---|
| 1.D | Gleiss M. (6.0) Lintner (7.5) |
6.75 | Grill (6.2) Veit-Egerer (6.6) |
6.40 | -0.35 | 33.0% | ✓ gewonnen |
| 2.D | Gleiss P. (6.5) Koll (7.0) |
6.75 | Rohm (6.6) Heimberger (7.3) |
6.95 | +0.20 | 60.0% | ✓ gewonnen |
| 3.D | Haselmayer (6.3) Hessel (8.1) |
7.20 | Soukup (6.8) Bauer (7.3) |
7.05 | -0.15 | 42.5% | ✓ gewonnen |
Mit p1=0.3303, p2=0.5996, p3=0.4248 rechnet sich:
P(genau 0) = 0.1542 P(genau 1) = 0.4210 P(genau 2) = 0.3407 P(genau 3) = 0.0841 Summe = 1.000000 ✓ P(≥1 Doppel-Sieg) = 84.58% P(≥2 Doppel-Siege) = 42.48% P(≥3 Doppel-Siege) = 8.41%
Real gespielt: 3 von 3 Doppel gewonnen. Das Modell hatte für ≥2 Siege ~42% Wahrscheinlichkeit vorhergesagt — eingetreten ist 3 → bei einem Einzelspiel sagt die Wahrscheinlichkeit nichts darüber aus, was passieren wird, sondern was im Schnitt über viele Spiele passieren würde.
7.2 · Was wäre Minimax-optimal gewesen?
Der Solver durchläuft alle 22×22 = 484 Szenarien. Für jede unserer Aufstellungen wird die für uns ungünstigste Gegner-Antwort identifiziert; daraus die Minimax-beste Wahl:
| D | Heim-Paar (Minimax) | Worst-Case Gast-Paar | pi |
|---|---|---|---|
| 1.D | Haselmayer (6.3) + Gleiss P. (6.5) · ⌀ 6.40 | Grill (6.2) + Rohm (6.6) · ⌀ 6.40 | 50.0% |
| 2.D | Gleiss M. (6.0) + Koll (7.0) · ⌀ 6.50 | Veit-Egerer (6.6) + Soukup (6.8) · ⌀ 6.70 | 60.0% |
| 3.D | Lintner (7.5) + Hessel (8.1) · ⌀ 7.80 | Bauer (7.3) + Heimberger (7.3) · ⌀ 7.30 | 26.7% |
- Garantiert P(≥1) 85.3%
- Garantiert P(≥2) 43.3%
- Garantiert P(≥3) 8.0%
7.3 · Drei verschiedene Wahrscheinlichkeiten — was bedeutet was?
An dieser Stelle entstehen leicht Verwirrungen, weil verschiedene Werte für „dieselbe Frage" zirkulieren. Sie sind aber nicht dasselbe:
Warum unterscheiden sich diese?
- 7.1 (42.5%) ist die Wahrscheinlichkeit für die tatsächlich gespielten Paarungen. Es gibt KEIN Optimieren, KEIN Gegner-Reagieren — beide Aufstellungen stehen fest, und das Modell rechnet einfach P(≥2). Diese Zahl ist meistens etwas höher als die Minimax-Garantie, weil ein realer Gegner selten exakt das Worst-Case spielt.
- 7.2 / 8.1 (43.3%) ist die Minimax-Garantie: für jede mögliche Gegner-Antwort haben wir mindestens diesen Wert. Konservativer, aber spielsicher.
- Best-Response (46.0%) ist, was theoretisch erreichbar wäre, wenn wir die Gegner-Aufstellung schon vorab gekannt hätten — also der Ober-Bound dessen, was Aufstellung gegen genau diese eine Gegner-Anordnung leisten kann.
Hier konkret: Real-Differenz = +0.85 pp zwischen tatsächlich gespielter Aufstellung und Minimax-Optimum. Wenn die Differenz negativ ist, hat der Gegner uns mit seiner Aufstellung „suboptimal" das Leben leichter gemacht; wenn positiv, hat er optimal aufgestellt und wir hätten besser anders paaren können.
7.4 · Wenn das Ziel „alle 3 Doppel" ist — andere Aufstellung?
Bei 2:4 Rückstand nach den Einzeln reicht uns ein 2:1 in den Doppeln nicht — wir müssen alle drei gewinnen. Der Captain wechselt das Ziel von T=2 auf T=3. Die optimale Aufstellung wird typischerweise anders, weil das Modell jetzt nicht mehr "den schwächsten Doppel-Pair akzeptieren" darf.
Für unser Krems-Süd 3 Beispiel ergibt der Solver:
Aufstellung für T=3 ("alle drei Doppel"):
| D | Heim-Paar | Worst-Case Gast-Paar | pi |
|---|---|---|---|
| 1.D | Gleiss M. (6.0) + Lintner (7.5) · ⌀ 6.75 | Grill (6.2) + Heimberger (7.3) · ⌀ 6.75 | 50.0% |
| 2.D | Gleiss P. (6.5) + Koll (7.0) · ⌀ 6.75 | Rohm (6.6) + Bauer (7.3) · ⌀ 6.95 | 60.0% |
| 3.D | Haselmayer (6.3) + Hessel (8.1) · ⌀ 7.20 | Veit-Egerer (6.6) + Soukup (6.8) · ⌀ 6.70 | 26.7% |
- Garantiert P(≥1) 85.3%
- Garantiert P(≥2) 43.3%
- Garantiert P(=3) 8.0%
Trade-off: Was kostet die T=3-Strategie?
Wenn man sich für die T=3-Aufstellung entscheidet, verschiebt sich das gesamte Wahrscheinlichkeits-Profil:
| Aufstellung | P(≥1) Minimax | P(≥2) Minimax | P(=3) Minimax |
|---|---|---|---|
| T=2-optimal — (2, 3, 1, 4, 5, 6) | 85.3% | 43.3% | 4.7% |
| T=3-optimal — (1, 5, 3, 4, 2, 6) | 85.3% | 42.7% | 8.0% |
Die T=3-Variante opfert +0.61 pp bei P(≥2), gewinnt aber +3.34 pp bei P(=3). Mathematisch: man verteilt die Wahrscheinlichkeitsmasse weg vom „mindestens 2"-Bereich hin zu „alle 3" — typischerweise indem man die Per-Doppel-Probs gleichmäßiger macht (man will keine schwachen Paare; in P(≥2) konnte man sich ein schwächeres Doppel "leisten", in P(=3) nicht).
Pointe für unser Match: die tatsächlich gespielte Krems-Aufstellung war Gleiss M.+Lintner / Gleiss P.+Koll / Haselmayer+Hessel — das ist identisch mit der T=3-Minimax-optimalen Aufstellung. Der Captain hat bei 2:4 Rückstand intuitiv den richtigen Modus gewählt und ist mit P(=3)=8.5% das (kleine!) Risiko eingegangen. Es ist aufgegangen.
7.5 · Wie variabel ist P(≥2) je nach Gegner-Reaktion?
Für unsere Minimax-Aufstellung (2, 3, 1, 4, 5, 6): alle 22 möglichen Gegner-Aufstellungen liefern P(≥2) zwischen 43.3% (Worst Case) und 51.9% (Best Case):
| Gegner-Aufstellung | P(≥1) | P(≥2) | P(≥3) |
|---|---|---|---|
| 5 ungünstigste für uns: | |||
| (1, 2, 3, 4, 5, 6) | 85.3% | 43.3% | 8.0% |
| (1, 3, 2, 4, 5, 6) | 85.3% | 43.3% | 8.0% |
| (2, 3, 1, 4, 5, 6) | 85.3% | 43.3% | 8.0% |
| (1, 4, 2, 3, 5, 6) | 85.2% | 43.5% | 8.1% |
| (1, 2, 3, 5, 4, 6) | 88.2% | 44.6% | 6.4% |
| 5 günstigste für uns: | |||
| (2, 4, 1, 5, 3, 6) | 88.7% | 47.4% | 6.1% |
| (2, 4, 1, 6, 3, 5) | 88.7% | 47.4% | 6.1% |
| (3, 4, 1, 6, 2, 5) | 88.7% | 47.4% | 6.1% |
| (2, 5, 1, 6, 3, 4) | 91.6% | 51.2% | 4.6% |
| (1, 6, 2, 5, 3, 4) | 91.4% | 51.9% | 4.7% |
7.6 · Verifikation: Monte-Carlo-Simulation
Quersicht der analytischen Formeln gegen 100.000 zufällige Simulationen mit den Per-Doppel-Wahrscheinlichkeiten der Minimax-Aufstellung (jedes Doppel wird unabhängig mit pi als „Sieg" ausgewürfelt):
| Analytisch | Monte-Carlo (100k) | Abweichung | |
|---|---|---|---|
| P(≥1) | 0.8533 | 0.8538 | 0.0005 |
| P(≥2) | 0.4333 | 0.4323 | 0.0010 |
| P(≥3) | 0.0800 | 0.0799 | 0.0002 |
Maximale absolute Abweichung: 0.0010 — innerhalb des Standardfehlers √(p(1-p)/N) ≈ 0.0016, also keine systematische Differenz. Die Formel rechnet korrekt.
Hinweis: alle Berechnungen verwenden den aktuellen MLE-Fit-Wert weight = 1.010 (gefittet auf 11171 NÖTV-Doppel-Matches). Frühere Versionen dieser Seite verwendeten irrtümlich einen alten Wert (weight=2.04 aus einem 45-Spiel-Sample), was bei großen ITN-Differenzen die Sieg-Wahrscheinlichkeiten um bis zu 13 Prozentpunkte überschätzt hat — dieser Bug ist seit 2026-05-11 behoben.
8 · Beste / schlechteste Aufstellung im Minimax-Sinn
Für vollständiges Bild: die Top-3 und schlechtesten 3 unserer 22 regelkonformen Aufstellungen (sortiert nach Minimax-P(≥2) — also Worst-Case-Garantie):
8.1 · Top 3 Aufstellungen (Minimax)
| Doppel | Wir | Worst-Case Gegner | P(Sieg) |
|---|---|---|---|
| 1.D | Haselmayer Gleiss P. |
Grill (6.20) Rohm (6.60) |
50% |
| 2.D | Gleiss M. Koll |
Veit-Egerer (6.60) Soukup (6.80) |
60% |
| 3.D | Lintner Hessel |
Bauer (7.30) Heimberger (7.30) |
27% |
| Doppel | Wir | Worst-Case Gegner | P(Sieg) |
|---|---|---|---|
| 1.D | Gleiss M. Koll |
Grill (6.20) Rohm (6.60) |
45% |
| 2.D | Haselmayer Gleiss P. |
Veit-Egerer (6.60) Soukup (6.80) |
65% |
| 3.D | Lintner Hessel |
Bauer (7.30) Heimberger (7.30) |
27% |
| Doppel | Wir | Worst-Case Gegner | P(Sieg) |
|---|---|---|---|
| 1.D | Gleiss M. Gleiss P. |
Rohm (6.60) Veit-Egerer (6.60) |
67% |
| 2.D | Haselmayer Koll |
Grill (6.20) Soukup (6.80) |
42% |
| 3.D | Lintner Hessel |
Bauer (7.30) Heimberger (7.30) |
27% |
8.2 · Die schlechtesten 3 Aufstellungen (zur Kontrastierung)
| Doppel | Wir | Worst-Case Gegner | P(Sieg) |
|---|---|---|---|
| 1.D | Gleiss M. Gleiss P. |
Rohm (6.60) Bauer (7.30) |
80% |
| 2.D | Haselmayer Hessel |
Grill (6.20) Heimberger (7.30) |
29% |
| 3.D | Koll Lintner |
Veit-Egerer (6.60) Soukup (6.80) |
25% |
| Doppel | Wir | Worst-Case Gegner | P(Sieg) |
|---|---|---|---|
| 1.D | Gleiss M. Haselmayer |
Rohm (6.60) Bauer (7.30) |
83% |
| 2.D | Koll Lintner |
Grill (6.20) Heimberger (7.30) |
27% |
| 3.D | Gleiss P. Hessel |
Veit-Egerer (6.60) Soukup (6.80) |
23% |
| Doppel | Wir | Worst-Case Gegner | P(Sieg) |
|---|---|---|---|
| 1.D | Gleiss M. Haselmayer |
Rohm (6.60) Bauer (7.30) |
83% |
| 2.D | Gleiss P. Hessel |
Grill (6.20) Heimberger (7.30) |
25% |
| 3.D | Koll Lintner |
Veit-Egerer (6.60) Soukup (6.80) |
25% |
9 · β ist nicht konstant — Variation mit dem ITN-Niveau
Bis hierher haben wir ein einzelnes β (gefittet auf alle Doppel: β ≈ 0.99 ITN) verwendet. Aber: ist β wirklich überall gleich? Wir können denselben MLE-Fit separat für jeden ITN-Bucket durchführen und schauen, was passiert.
Visuell wird der Unterschied am deutlichsten, wenn wir zwei Bereiche direkt nebeneinander stellen — die Profi-nahen Spieler (ITN 2–3) und die typische Allgemeine Klasse (ITN 5–6):
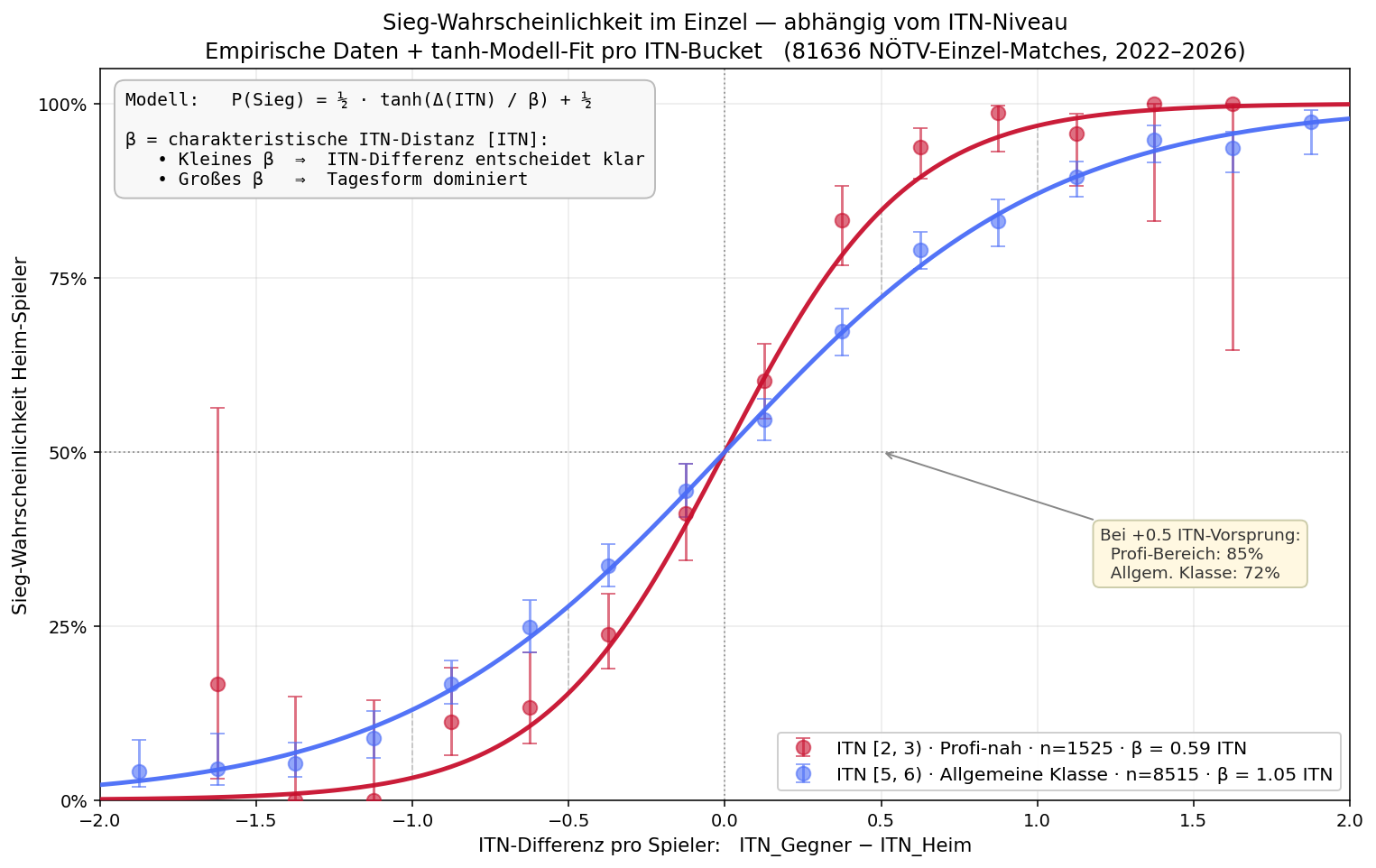
Beide Punktwolken sind empirisch (NÖTV-Daten, mit Wilson-95%-CIs); die durchgezogenen Linien sind die jeweiligen tanh-Fits. Die rote Profi-Kurve ist deutlich steiler als die blaue Allgemeine-Klasse-Kurve — bei +0.5 ITN-Vorsprung gewinnt der Profi mit ~85%, in der Allgemeinen Klasse aber nur mit ~73%. Dieselbe ITN-Differenz, doppelt so viel Aussagekraft im Profi-Bereich — was sich in einem kleineren β (charakteristische Distanz) im Profi-Bereich niederschlägt.
Datenbasis dieser Auswertung: 81636 Einzel · 38551 Doppel. Pro ITN-Bucket (definiert über das Per-Spieler-Mittel der beiden) wird β separat per Maximum Likelihood gefittet, 95%-Konfidenzintervall via Bootstrap (200 Resamples). Kleines β (in ITN) = berechenbarer.
| ITN-Bucket | Einzel | Doppel | ||||
|---|---|---|---|---|---|---|
| n | β [ITN] | 95%-CI | n | β [ITN] | 95%-CI | |
| [1, 2) Profi | 444 | 0.44 | [0.36, 0.54] | 157 | 0.57 | [0.35, 1.02] |
| [2, 3) Profi | 1525 | 0.59 | [0.52, 0.65] | 597 | 0.71 | [0.60, 0.83] |
| [3, 4) | 3240 | 0.76 | [0.70, 0.82] | 1378 | 0.89 | [0.78, 1.00] |
| [4, 5) | 5674 | 0.89 | [0.85, 0.94] | 2516 | 1.05 | [0.97, 1.15] |
| [5, 6) | 8515 | 1.05 | [1.00, 1.11] | 3744 | 1.07 | [0.99, 1.13] |
| [6, 7) | 12501 | 1.19 | [1.14, 1.24] | 6005 | 1.21 | [1.14, 1.27] |
| [7, 8) | 15553 | 1.28 | [1.24, 1.33] | 8172 | 1.15 | [1.10, 1.20] |
| [8, 9) | 15490 | 1.20 | [1.15, 1.24] | 8625 | 1.01 | [0.96, 1.05] |
| [9, 10) Anfänger | 14673 | 0.93 | [0.90, 0.98] | 6561 | 0.74 | [0.69, 0.78] |
| [10, 11) Anfänger | 4021 | 0.99 | [0.87, 1.18] | 796 | 0.64 | [0.50, 0.88] |
Hinweis: kleine β-Zahl = sehr berechenbar (schon kleine ITN-Differenz entscheidet); große β-Zahl = unberechenbar / Tagesform dominiert. Die 95%-CIs sind durch die 1/β-Transformation in der Reihenfolge gespiegelt (CI_lo aus 1/β_hi etc.).
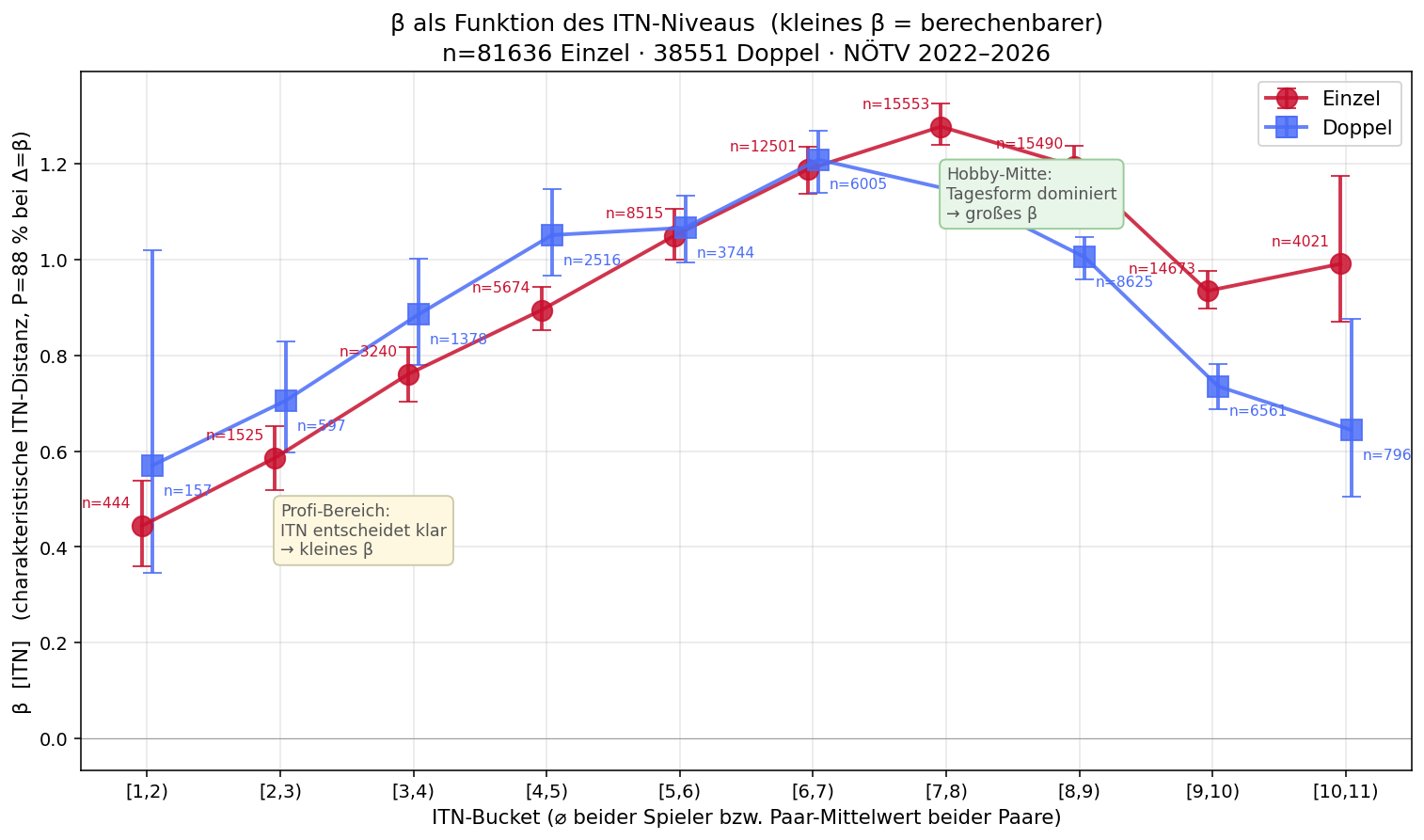
Das Bild ist eindeutig — β bildet eine umgekehrte U-Kurve (in der neuen Notation):
- Profi-Bereich (ITN 1–3): β ≈ 0.5–0.6 ITN — schon eine halbe ITN-Stufe entscheidet klar. Spieler in diesen Klassen liefern konsistent ab.
- Hobby-Mitte (ITN 7–8): β ≈ 1.2 ITN — Maximum. Hier braucht es mehr ITN-Differenz für das gleiche 88%-Niveau. Tagesform dominiert.
- Anfänger-Bereich (ITN 9–11): β sinkt wieder auf 0.5–0.8 ITN. Wer den Ball regelmäßig reinbringt, gewinnt — Erfahrungs-Differenzen entscheiden eindeutig.
Statistisch hoch signifikant: die 95%-CIs von Profi-β (≈ [0.5, 0.7] ITN) und Hobby-Mitte-β (≈ [1.1, 1.25] ITN) überlappen nicht — der Unterschied ist robust und nicht Daten-Zufall.
9.1 · Was bedeutet das praktisch?
Für den Doppelrechner heißt das: der globale β-Wert (≈ 1.0 ITN) ist ein Kompromiss, der für die ITN-Mitte (wo die meisten Daten liegen) gut passt, aber Wahrscheinlichkeiten in den Extrembereichen leicht verzerrt:
- Im Profi-Bereich wird die echte Sieg-Wahrscheinlichkeit unterschätzt (β=1.0 ITN ist zu groß — bei +0.5 ITN-Vorsprung sind echte 80% statt modellierter 73%).
- Im Hobby-Mitte-Bereich wird sie leicht überschätzt (β=1.0 ITN ist zu klein — bei +0.5 ITN sind echte 65% statt modellierter 73%).
Eine adaptive Variante des Doppelrechners könnte das Team-Mittel als ITN-Niveau verwenden und den entsprechenden β-Wert aus dieser Tabelle ziehen. Bei unserer 3. Mannschaft (Team-Mittel ≈ 6.5) wäre β ≈ 1.1 ITN das passende Modell — sehr nahe am globalen Wert. Bei der 1er-Mannschaft (Team-Mittel ≈ 3.2) wäre β ≈ 0.7 ITN angemessen — die Modell-Prognosen würden etwas „decisiver".
9.2 · Physikalische Analogie
In der statistischen Physik tritt der Boltzmann-Faktor exp(−E/kT) auf — niedrige Temperatur T bedeutet, dass Energieunterschiede klare Konsequenzen haben (deterministisches Verhalten). Hohe Temperatur bedeutet, dass auch energetisch ungünstige Zustände erreicht werden (zufälliges Verhalten).
Hier ist β das Analogon zur inversen Temperatur β = 1/(kT):
- Hohes β (Profi/Anfänger) = niedrige „Tennis-Temperatur" = ITN-Niveau entscheidet deterministisch
- Niedriges β (Hobby-Mitte) = hohe „Tennis-Temperatur" = thermische Fluktuationen (Tagesform) dominieren
9.3 · Spread innerhalb des Paars — überrascht das Modell?
Bisher hat das Modell nur den Paar-Mittelwert verwendet — also (ITNP1 + ITNP2) / 2. Eine Paarung 3.5 + 3.5 wird dabei genauso behandelt wie 2.0 + 5.0, obwohl die zweite Variante intuitiv „anders" wirkt. Hat das tanh-Modell hier eine Lücke?
Wir können das prüfen: pro Doppel-Match berechnen wir die Modell-Prognose PModell aus dem Paar-Mittel und vergleichen mit dem tatsächlichen Sieg-Anteil. Wenn die Spread keine Rolle spielt, sollte das Mittel-Residuum (= tatsächlich − Modell) bei allen Spread-Bins um 0 streuen. Andernfalls hat das Modell einen blinden Fleck.
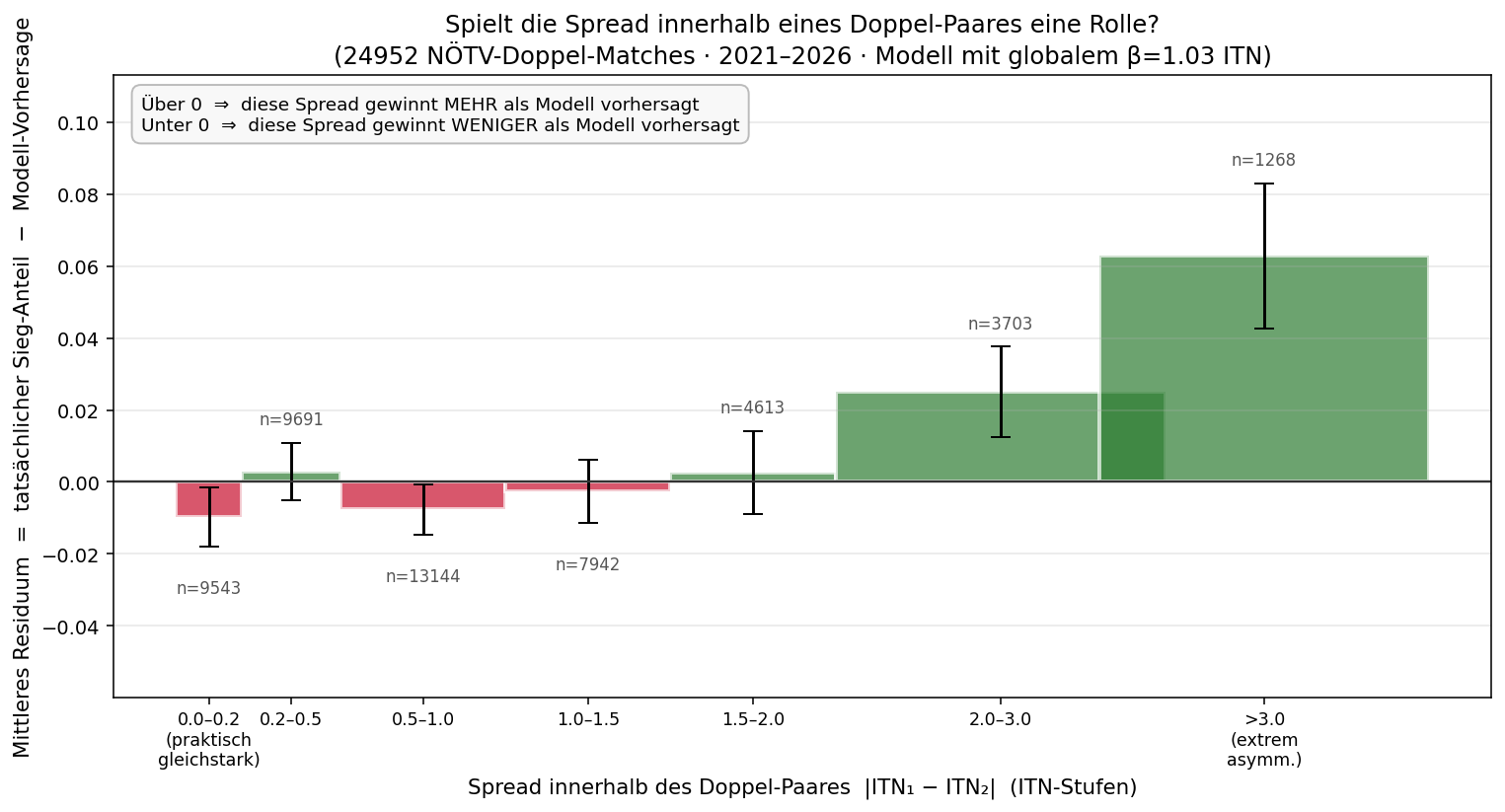
Das Bild ist klar: bei sehr ungleichen Paarungen (Spread > 2 ITN-Stufen) gewinnt das Paar systematisch mehr als das Modell vorhersagt — bei Spread > 3 ITN sogar +6.3 Prozentpunkte über der Modell-Erwartung. Balancierte Paarungen (Spread < 0.5) liegen dagegen leicht unter der Prognose.
Verhältnis ⟨Pactual⟩ / ⟨PModell⟩ pro Spread-Bin
Wir messen pro Spread-Bin den tatsächlichen Sieg-Anteil ⟨Pactual⟩ dividiert durch den Modell-Mittelwert ⟨PModell⟩ derselben Matches (das Modell variiert ja mit dem jeweiligen Begegnungs-Schwierigkeit diff). Ratio = 1 hieße: das Paar-Mittel-Modell ist exakt. Beschränkt auf Paar-Mittel 4–7 ITN (mittlerer Bereich):
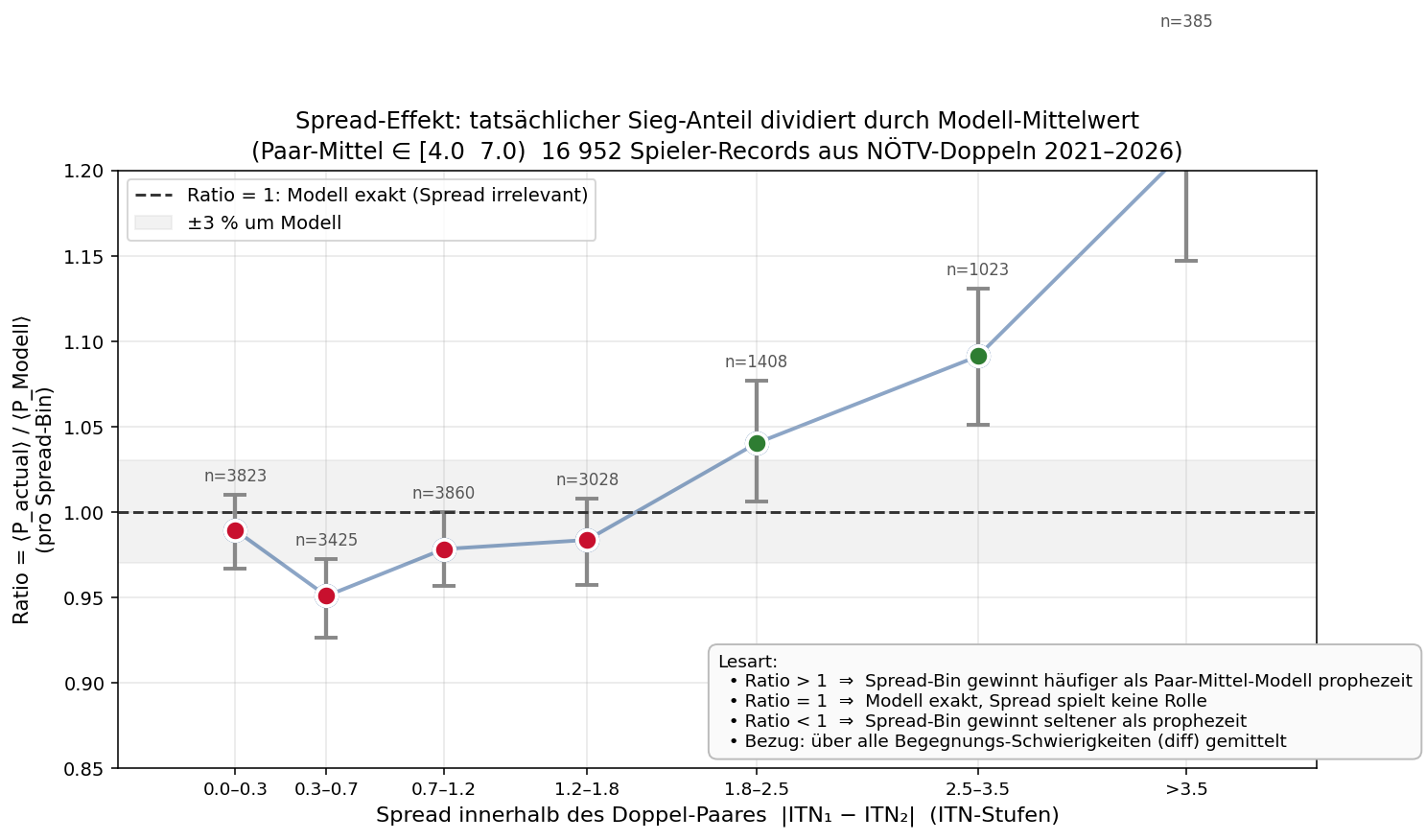
U-förmiger Verlauf: ausgeglichene Paare (Spread 0.0–0.3) sind nahe Ratio 1 — Modell stimmt für sie. Leicht asymmetrische Paare (Spread 0.3–0.7) gewinnen 5 % weniger als das Modell prophezeit — eine Art „worst of both worlds": beide ähnlich stark, aber nicht gleich, keiner übernimmt klar die Führung. Erst ab Spread ≈ 1.8 dreht sich das Ratio ins Positive, und bei Spread > 3.5 wird der Bonus deutlich (+21 % über Modell).
Daraus folgt: halbe Sachen sind statistisch das Schlechteste. Wenn du eine asymmetrische Paarung wählst, dann richtig asymmetrisch (klare Rollenverteilung); andernfalls lieber bewusst ausgeglichen.
Konkret in Zahlen — beobachtete Werte aus dem mittleren ITN-Bereich:
| Aufstellung | Beispiel | Spread | ⟨Pactual⟩ | ⟨PModell⟩ | Ratio |
|---|---|---|---|---|---|
| Ausgeglichen | 4.5 + 4.5 | 0.0–0.3 | 57.9 % | 58.5 % | 0.99 |
| Leicht ungleich (Falle!) | 4.2 + 4.8 | 0.3–0.7 | 55.8 % | 58.7 % | 0.95 ⬅ schlechter |
| Mittel ungleich | 4.0 + 5.0 | 0.7–1.2 | 56.6 % | 57.9 % | 0.98 |
| Eindeutig ungleich | 3.5 + 5.5 | 1.8–2.5 | 58.7 % | 56.5 % | 1.04 |
| Stark ungleich | 2.5 + 6.5 | 2.5–3.5 | 61.1 % | 56.0 % | 1.09 |
| Extrem ungleich | 2.0 + 7.0 | >3.5 | 67.0 % | 55.3 % | 1.21 |
Die ⟨Pactual⟩-Werte sind höher als 50 %, weil im mittleren ITN-Bereich oft gegen leicht schwächere Gegner gespielt wird (positives diff im Schnitt). Der ⟨PModell⟩-Wert ist die durchschnittliche tanh-Vorhersage über genau die gleichen Begegnungen — direkter Vergleich.
Pstark-ungleich / Pausgeglichen ≈ 1.14 — eine stark asymmetrische Paarung gewinnt im Schnitt etwa 14 % relativ häufiger als eine ausgeglichene mit demselben Paar-Mittel.
Der Effekt ist im Profi- und Mittel-Bereich (ITN 2–7) klar sichtbar (+3 PP), im Hobby-Schwach-Bereich (ITN 7–11) nicht messbar (~0). Plausibel:
- Captain-Effekt: in einer asymmetrischen Paarung übernimmt der stärkere Spieler die Schlüsselbälle (Aufschlag-Volley, Returns), der schwächere kann sich auf weniger Verantwortung konzentrieren. Bei zwei gleichstarken Spielern ist die Arbeitsteilung weniger eindeutig.
- Eingespielte Paare: stark unterschiedliche Paarungen sind selten zufällig — meist sind sie taktisch gesetzt (Mentor + Junior, Aufschläger + Returnierer) und entsprechend eingespielt.
- Modell-Bias an den Rändern: das tanh-Modell ist auf homogene Paarungen kalibriert; bei großer interner Heterogenität versagt es systematisch nach oben.
Praxis-Implikation: bei der Aufstellungs-Wahl ist eine asymmetrische Paarung gegenüber einer ausgeglichenen mit demselben Paar-Mittel statistisch im Vorteil. Wenn die NÖTV-Regeln es zulassen, kann das ein zusätzliches taktisches Argument sein — z. B. einen 3.0er + 6.0er-Spieler als 2. Doppel zu paaren statt zwei 4.5er, sofern beide Optionen regelkonform sind.
Caveat: bei Spread > 3 ist die Stichprobe klein (1 268 Records). Die +6.3-PP-Aussage ist statistisch signifikant (~6 σ über null), aber die genaue Höhe könnte sich mit mehr Daten noch verschieben.
9.4 · Warum Doppel-ITN bei vielen schlechter aussieht als Einzel-ITN — systematischer ITN-Drift
Bei der Doppel-ITN-Berechnung fällt auf: viele Spieler haben eine höhere (= schlechtere) Doppel-ITN als ihre aktuelle Einzel-ITN. Auf den ersten Blick wirkt das wie ein Bug. Tatsächlich ist es aber ein bekanntes Artefakt der ÖTV-ITN-Systematik. Hier die Datenlage:
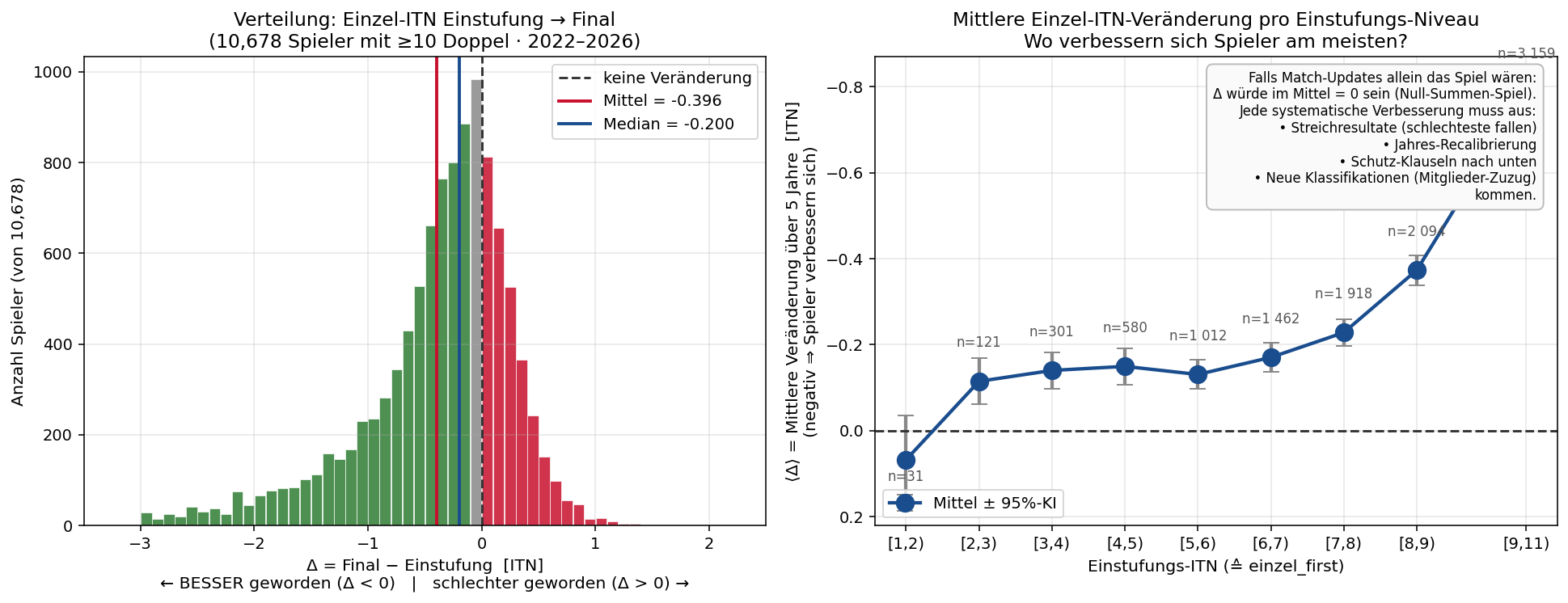
Befund: Über alle 10 678 qualifizierten Spieler ist die mittlere Einzel-ITN-Verbesserung −0.40 ITN-Stufen über 5 Jahre, Median −0.20. 62.7 % der Spieler haben ihre Einzel-ITN verbessert, nur 28.1 % verschlechtert.
| Einstufungs-Bucket | n | ⟨Δ⟩ [ITN] | Median |
|---|---|---|---|
| [1, 2) Profi-nah | 31 | +0.07 | 0.00 |
| [2, 3) | 121 | −0.12 | −0.10 |
| [3, 4) | 301 | −0.14 | −0.10 |
| [4, 5) | 580 | −0.15 | −0.10 |
| [5, 6) | 1 012 | −0.13 | −0.10 |
| [6, 7) | 1 462 | −0.17 | −0.10 |
| [7, 8) | 1 918 | −0.23 | −0.10 |
| [8, 9) Hobby | 2 094 | −0.37 | −0.20 |
| [9, 11) Anfänger | 3 159 | −0.79 | −0.50 |
Warum müsste das eigentlich ≈ 0 sein? Reine Match-Updates sind ein Null-Summen-Spiel: für jeden Punkt, den der Sieger gut macht, verliert der Verlierer denselben Betrag. Wenn ich also alle Δ über alle Spieler aufsummiere, müsste es im Schnitt bei null landen. Tut es aber nicht — die ITN driftet im NÖTV-System systematisch nach unten (= besser). Der Drift ist umso stärker, je höher die Einstufungs-ITN.
Mögliche Quellen des Drifts:
- Streichresultate — bei vielen Match-Bewerben fallen die schlechtesten Resultate automatisch weg; übrig bleiben die guten → ITN-Verbesserung ohne Skill-Verbesserung.
- Jahres-Recalibrierung — der ÖTV passt zum Jahreswechsel Klassengrenzen an. Ergebnis: pauschale Verschiebungen für ganze Klassen.
- Echte Skill-Verbesserung — Anfänger lernen über 5 Jahre real dazu. Das erklärt den deutlich höheren Drift in den schwachen Buckets.
- Schutz-Klausel nach unten — bei Top-Spielern kann die ITN pro Jahr nur begrenzt schlechter werden; Niederlagen werden teilweise abgefangen.
Konsequenz für die Doppel-ITN-Berechnung auf dieser Seite: Mein Algorithmus aktualisiert die Doppel-ITN nur über die direkte ÖTV-Match-Formel ohne Streichresultate, Recalibrierungen oder Schutzklauseln. Dadurch verpasst die berechnete Doppel-ITN denselben systematischen Drift, den die Einzel-ITN über die NÖTV-Algorithmen mitbekommt. Bei vielen Spielern erscheint die Doppel-ITN deshalb um typischerweise +0.2 bis +0.4 ITN-Stufen schlechter als die Einzel-ITN — nicht weil sie wirklich schlechter im Doppel sind, sondern weil die Einzel-ITN dank ÖTV-Glättung „künstlich besser" ist.
Korrekturregel von Hand: Wenn man die berechnete Doppel-ITN auf die NÖTV-Skala übersetzen möchte, kann man grob den oben tabellierten Drift abziehen. Für einen ITN-7-Spieler also ca. Doppel-ITN_korrigiert ≈ Doppel-ITN_berechnet − 0.23; für einen ITN-9-Spieler ca. − 0.79. Das ist natürlich nur eine Mittelwert-Korrektur; individuelle Unterschiede bleiben.
10 · Was die Daten lehren
Konkrete Annahmen die wir treffen: (1) Die drei Doppel sind stochastisch unabhängig — d.h. ein Sieg im 1. Doppel beeinflusst die Wahrscheinlichkeit im 2. Doppel nicht. Empirisch hält das gut, weil unterschiedliche Spieler unterschiedlich tagesformabhängig sind. (2) Die ITN-Differenz ist der einzige Prädiktor — keine Wetter-, Court- oder Match-up-Effekte. (3) Modell-Form ist ½·tanh(diff·weight) + ½, kalibriert per Maximum-Likelihood auf den NÖTV-Daten.
- Tennis-Doppel ist deterministisch. Bei ≥0.5 ITN-Paar-Mittel-Vorsprung (entspricht ~1.0 ITN-Summen-Vorsprung) gewinnst du in 82–100% der Fälle. Bei ≥1.0 ITN-Paar-Mittel-Vorsprung praktisch immer.
- Gleichauf ist gefährlich. Bei ITN-Paar-Mittel-Differenz nahe 0 ist's 36–50% — pure Lotterie.
- Captain-Entscheidungen machen Prozentpunkte aus. In unserem Beispiel: 6.1 Prozentpunkte zwischen bester und schlechtester regelkonformer Aufstellung. Über eine Saison summiert sich das.
- Minimax-Strategie schützt vor der besten Antwort des Gegners. Wer nur auf den naiven Erwartungswert optimiert, geht ein Risiko ein.
- Die NÖTV-Regel (§7 Abs. 11) lässt nur 22 von 90 möglichen Anordnungen zu. Spieler 1 muss in 1.D oder 2.D spielen, die Paar-Summen müssen aufsteigend sein — das schränkt den Spielraum deutlich ein.
Eigene Aufstellung berechnen?
Zum Doppelrechner